micro.blog is a great platform. However, GitHub is kind of my “home” when it comes to both my hobbies and work. Moving everything to GitHub Pages also brings a more flexibility on how I want my “landing page” on the Internet to look like and contain. I’ve set up my GitHub Pages repo with Jekyll. I use the amazing Minimal Mistakes theme by Michael Rose. By using Jekyll, I don’t need no stinkin’ backend to store my stuff. The whole blog is mine, and I can take it and host it wherever I like. There’s no database to worry about or anything – just markdown (and some yaml for configuration).
For those that are not familiar with Jekyll, it’s a static site generator written in Ruby. I write my posts and pages in markdown, and pages and links are generated by rendering them to HTML. In fact, micro.blog is, as far as I know, powered by Hugo, another static site generation framework. I’m certainly not a Ruby guy - but thankfully there’s no need to do any Ruby coding – only markdown and yaml.
I’ve made my little browser-based game Gravistroids available from GitHub Pages at: https://hallgeirl.github.io/gravitroids/. There’ll be instructions on the site with a link to start the game. Crash gently!
You may or may not know, but I’ve made myself a coffee roaster. Currently it has about 30kg of coffee behind it, so it’s doing its job well. It is controlled through the Artisan roasting software, and I used an Arduino to set this up. I’ve created a github repo for this project: https://github.com/hallgeirl/coffee-roaster, and I’ve recently cleaned up the docs a bit. Don’t hesitate to ask if you have questions about this.
Did you know you can merge a git repo into a subfolder of another, while keeping the commit history of the repo you’re merging in? It was surprisingly simple. Here’s how you do it:
# Navigate to the repo folder where you're merging intocd path-to-destination-repo
# Add a remote that points to the repo you're merging in (replace <repo-url> with the actual URL obviously)
git remote add tobemerged <repo-url>
# Fetch changes from the new remote
git fetch tobemerged
# Merge the changes from remote master, but don't commit, and keep the changes from destination.# This shouldn't actually do anything to the destination repo filesystem.
git merge -sours--no-commit--allow-unrelated-histories tobemerged/master
# Read the files from the repo you're merging in, and put them in the specified subfolder
git read-tree --prefix=subfolder/for/merge/ -u tobemerged/master
# Commit the merge
git commit -m"Merged repos"
That’s it! You should get the full git log from both repos with git log.
IdentityServer is quite an awesome framework for creating your own OAUTH-based authentication server in .NET Core. At its core, its purpose is to provide OAUTH endpoints to allow clients request access tokens to then call APIs. IdentityServer also supports being used as a federation gateway, by utilizing the built-in authentication system in .NET Core.
This is great if you’re creating an authentication server that has a fixed number of authentication providers that serves applications that should use the same authentication providers, or a subset of these. However, in some scenarios, like the one I have in my own organization, where we allow customers to bring their own authentication, using OpenID Connect or WS Federation. We have a lot of customers on our cloud solution, so setting up each of the authentication providers statically in the authentication server is not going to work.
There’s some resources for this online, but it was hard to find concrete examples for how to achieve this. Here’s a few tips that might be helpful if you’re trying to achieve this in your application. I’ll show the steps here for implementing federated OpenID Connect here, but the steps for adding support for WS Federation is more or less exactly the same (just swap out “OpenIdConnect” with “WsFederation” in most of the class names).
The setup
We will define our authentication services in our ConfigureServices method:
Notice that we don’t just do AddOpenIdConnect() - we want to register a custom OpenIdConnectHandler that is multi-tenant aware. We’ll get back to those details soon. Also notice that we register a custom IOptionsmonitor<OpenIdConnectOptions> and IConfigureOptions<OOpenIdConnectOptions> class. These will be used to fill in the client ID, authority and other parameters needed to authenticate at runtime.
Then we’ll configure the login URL for IdentityServer:
The /api/challenge/redirect endpoint will resolve which authentication service to be used for a tenant, based on acr_values where we will add the tenant ID.
Given all this, the authentication flow will be as follows:
Initial page load
Redirect to /connect/authorize?…
Redirect to /api/challenge/redirect?returnUrl=… - this looks up the authentication scheme to be used (e.g. openid-connect or ws-federation based on tenant ID, which we send through acr_values).
Redirect to /api/challenge?scheme=…&returnUrl=…&tenantId=….
Redirect to /api/challenge calls Challenge() with the specified scheme and returnUrl, which invokes the ASP.NET Core authentication mechanisms.
Redirect to external auth provider. This is where the user logs in with username+password.
Redirect to callback /signin-oidc/
Redirect to the page you wanted to load.
The challenge endpoint
First we need to create an endpoint to route the user to an endpoint which authenticates the user. This involves a lookup in a DB or something similar to get the ASP.NET Core authentication scheme for that tenant. We pass the tenant ID as in acr_values. More on that later.
[HttpGet][Route("redirect")]publicasyncTask<IActionResult>Redirect(stringscheme,stringreturnUrl){varauthContext=await_interaction.GetAuthorizationContextAsync(returnUrl);vartenantId=authContext.Tenant;// Look up the tenant's authentication provider here. This can be a database lookup. This should resolve to either: openid-connect or ws-federationvarscheme=GetAuthenticationSchemeForTenant(tenantId);returnRedirect(string.Format("/api/challenge?scheme={0}&tenantId={1}&returnUrl={2}",theScheme,tenantId,Uri.EscapeDataString(returnUrl)));}
Then for the actual challenge endpoint, it’s quite bare bone. Note that you should validate the input here (return URL, etc.), but for brevity, I’ve excluded this here. This is very standard, almost taken straight out of the quickstart UI for IdentityServer4.
Set options.CallbackPath to “/signin-oidc/” + tenantId; That way, after authentication, tenants are redirected to a tenant-specific endpoint.
When there’s no tenant ID, just set it to /signin-oidc. This happens on the first configuration call.
As for the tenant provider described in this StackOverflow post, for my usecase this doesn’t work because not all URLs are prefixed with the tenant ID. Perhaps that could be done in IdentityServer - but I opted for a different solution. Here’s the solution I went with for TenantProvider:
publicTenantAuthOptionsGetCurrentTenant(){varrequest=_httpContextAccessor.HttpContext.Request;stringtenant=null;PathStringremainingPath;if(request.Query.ContainsKey("tenantId"))tenant=request.Query["tenantId"];//OpenID Connectelseif(request.Path.StartsWithSegments(newPathString("/signin-oidc"),StringComparison.InvariantCultureIgnoreCase,outremainingPath))tenant=remainingPath.Value.Trim('/');//Do the DB lookup for the tenant authentication options (client ID, etc.)returnGetTenant(tenant);}
Here we look for the tenant ID in various places:
If it’s set on the query string, we get it from there. That’s needed when you redirect from /api/challenge/redirect to /api/challenge. You COULD probably add the tenant ID to the path on this endpoint instead. That’s up to you, and then you wouldn’t need to parse the query string.
If we’re at the signin-oidc endpoint, we get the tenant ID from the path.
The multi-tenant OpenIdConnectHandler
As mentioned previously, we can’t use the built-in OpenIdConnectHandler in our usecase. The reason is (and I don’t know WHY), is that some of the configuration options for the OpenIdConnectHandler is fetched per request, other values are cached seemingly forever after retrieving the configuration once. Most notably, the callback URL: If you use standard OpenIdConnectHandler, it will redirect correctly to /signin-oidc/(tenant-id), however, ShouldHandleRequestAsync() in the OpenIdConnectHandler() will return false, because apparently the CallbackPath is cached. Because of this, the handler won’t handle the /signin-oidc/(tenant-id) requests, and you’ll get a HTTP 404. I haven’t looked into the details on WHY this is, but this is thankfully easily solvable:
publicclassMultitenantOpenIdConnectHandler:OpenIdConnectHandler{publicMultitenantOpenIdConnectHandler(IOptionsMonitor<OpenIdConnectOptions>options,ILoggerFactorylogger,HtmlEncoderhtmlEncoder,UrlEncoderencoder,ISystemClockclock):base(options,logger,htmlEncoder,encoder,clock){}publicoverrideasyncTask<bool>ShouldHandleRequestAsync(){if(awaitbase.ShouldHandleRequestAsync())returntrue;// We expect a path on the format: <callbackpath>/<tenant-id>PathStringremaining;if(!Request.Path.StartsWithSegments(Options.CallbackPath,StringComparison.InvariantCultureIgnoreCase,outremaining))returnfalse;// The remaining segment should only have one path segment (== the tenant)returnremaining.Value.Trim('/').Split('/').Length==1;}}
In other words, we just parse the request path, treating the CallbackPath as the base. The original code in the framework uses a simple equality check, which fails in this case.
In conclusion
And this is pretty much it! I have based my implementation on the quickstart UI, so if you’re new to IdentityServer I certainly advise you to start exploring that FIRST before attempting this crazyness right here.
I hope this is of use to anyone. It certainly has been a learning experience for me.
I dug up some of my old coding projects this weekend. Oh boy, there’s lots of weird stufff I’ve been making over the years, especially in my early youth. But there’s some cool things as well. For instance, I made a Mario clone in C++ complete with a map editor and everything. Trying to get this project to compile were not simple 12 years later. Libraries were missing, were hard to find, and had moved on to newer versions. My environment has changed - back then I mostly used Linux, but for various reasons I now use Windows. With that I’d like to reflect on a couple of topics that I came to think about during the process of getting my project up and running again.
The newer C++ standards are quite awesome
Back in 2008, C++11, and certainly not C++17, were obviously not written yet. I had to rely on Boost libraries for things like smart pointers. There were no “foreach”-like syntax. Now, iterating arrays are just as easy as in other languages that include a foreach-syntax:
This seems super trivial today, where this kind of syntax is standard, and I would argue it’s more or less expected from a language today to include this kind of syntax. Back in 2008 however, having most of my experienced in C++, this was not the case. Smart pointers are also a very welcome addition to the C++ standard family!
Additionally, much functionality has been added to the standard libraries. To mention a couple that I’ve started using now, are std::filesystem and std::chrono for directory traversal and frame timing in my game, respectively. I had to rely on boost for a lot of things, and timing functions were mostly platform specific.
Garbage collection? I don’t miss you
In .NET, Java, Javascript and many other languages, you have a garbage collector running for you to ensure that objects you allocate on the heap are deallocated when no one are referencing them anymore. This is great - but it does have a performance cost. For large projects with a lot of object allocations, the garbage collection cycle can negatively impact performance.
With C++, you have no garbage collector. You need to manage the heap yourself. If you have a “new”, you need a “delete”, or else you get a memory leak. However, a common best practice in C++ is to avoid dynamic memory allocations as much as you can, which significantly limits this problem, and in some cases even removes it completely. Instead, C++ objects are allocated on the stack. Objects on the stack gets deleted when the stack frame is “done”. For instance, local objects defined in a function are deallocated when the function returns (unless you allocate objects on the heap, which you shouldn’t).
So what’s great about this? Well, the obvious one is that you no longer NEED a garbage collector. I find it strangely comforting to know exactly how long my objects live - and I don’t need to hypothesize if the high memory usage of my application is because the garbage collector hasn’t run yet, or if I actually have a memory leak. Stack allocation just is so comfortable. It’s not perfect if you need heap-allocated objects, however. I will aim to get rid of most or all heap allocations though.
CMake
I based my old game project on Makefiles. This is great - if you’re running on Linux. But Makefiles haven’t really been the “standard” on Windows. I’m sure you could use them somehow, though. But I wanted to find a proper cross-platform alternative - and that alternative is CMake. CMake is great - it’s fully supported in Visual Studio, is cross-platform and, in my opinion, has a much cleaner syntax than Makefiles. Here’s a minimal example:
This doens’t do much of course, other than compiling CMakeTest.cpp into an executable CMakeTest. It’s super simple to also add include paths and link paths to the target.
CMake were around in 2008, but I was not aware of it, or perhaps didn’t see the value. I’ll be using CMake from now on.
Cross-platform is king
People sometimes switch operating systems, for various reasons. I switched from Linux to Windows after I started working in my current organization, which is mainly a Windows shop. I also enjoy gaming, and back then gaming on Linux were not that mature (and it still has its issues). Anyway, I made my game project to be cross platform from the start using SDL. This was one of the best decisions I made for this projects I think - because it allowed me to get it up and running on my current machine without TOO much hassle.
In general, I really want software to be cross-platform. Why shouldn’t it be? WHY are for instance game developers NOT making their games available on Linux, when it’s really not that hard? C++ is quite portable, after all. Anyhow, for me, this makes a lot of sense. I believe that if you work towards cross-platform compatibility you will also have a better, more standardized code base, because you can’t rely on platform-specific hacks to get it to work.
We’re working hard to make our product cross-platform in my professional work as well.
Dependency management in C++ is still a nightmare :-)
I’ve been spoiled the last few years. I’ve worked with .NET, and here we have a solid package manager called Nuget. Do you need a new dependency, for instance a JSON library? Install it with Nuget, and it’ll work for everyone using this project.
C++ is a different beast. Perhaps with C++20 and the new concept of “modules”, there’s a chance of some innovation on this area, but currently it’s NOT possible to just “download, build and run” a project. You need to download the project, then install all sorts of dependencies, and their dependencies. For instance, “luabind” which I use in my project, depends on boost. boost itself is HUGE, but it needs to be installed. I need to install SDL. Then I need to install SDL_Mixer and the LUA libraries. Then MAYBE it’ll work. And this is my own SMALL project.
C++ needs a standard way of handling dependencies, in my opinion. I have a strong opinion that ALL you should need to do to build a project, is to download it from github, and run CMake (or whatever build tool you got). Dependecies should be fetched automatically.
The way to achieve this today would be to either include the source in your project (directly, or as git submodules), or to include libraries for each platform in the repository itself. The first option is probably the most portable - but perhaps not all libraries HAVE the source available. And there could be a LOT of dependencies, because dependencies has dependencies.
What many does however is to require that dependencies are installed on your system before compiling. For Linux users, this is probably not a bad way to go, as you can typically get a hold of these dependencies using your package manager. For Windows however, this can be a daunting task, to hunt down binaries and headers for all libraries that you need, and configure include and linker paths for these.
In my own project, this is an unsolved problem however. Some libraries (LUA and luabind) are included. Some are not.
How little I knew…
Since 2008, I’ve worked 8 years as a professional software developer. Before this, my programming experience were my own hobby projects starting in elementary school and onwards, as well as academic projects. There’s quite a leap going from these smaller projects, to giant enterprise-level software that NEEDS to be up and running for hundreds of thousands of users, every single hour of every single day. It’s fun to go back to look at my older projects and see how my coding style has changed over the years.
Wrapping up
Well… I don’t expect anyone to learn a lot of new things here, since I’m discussing my own ancient project and my reflections around this, but I’m always eager to discuss any of these topics. Feel free to reach out on Twitter!
For the record - here’s my coveted game project. It builds and runs (at least on Windows at the moment) after I switched to CMAKE and included some dependencies. You will have to install boost as well though. For Linux, you will have to install SDL and SDL_Mixer too.
Sometimes, moving your project from .NET Framework to .NET Core can be super easy, and sometimes it can be a daunting task. There’s several factors that can complicate matters:
Having .NET Framework only-components like Windows Communication Foundation (WCF) or Workflow Foundation in your project.
The project is heavily based on ASP.NET with a lot of HTTP modules and other ASP.NET (Framework version)-only constructs.
The project uses ASP.NET WebForms, which may never be supported.
The project is simply HUGE and complicated in itself.
Using third-party components that are not compatible with .NET Core.
We’re going through the motions of porting our main software product to .NET Core in my current organization at the moment and figured I’ll share a few tips based on our learnings so far.
To set the scene, we develop a .NET based case and document management solution that is used by local, regional and national governments and organizations in the nordics. It’s developed on .NET Framework, has 20 years of legacy, and ticks all the boxes above. We’re porting it to .NET Core for cross-platform hosting, future proofness and performance. One of the goasl is to run our software on Linux containers on Kubernetes, instead of having to rely on Windows-based containers, which has its issues.
You may have a monolithic application that is hard to port all at once. You may need to maintain it and release new functionality while you are doing the work on porting it, and porting it may be complex and take a long time itself.
What we’ve done here is:
Convert all project files (.csproj files) to the new project format introduced in Visual Studio 2017. Here’s a quick guide on how to do this: https://natemcmaster.com/blog/2017/03/09/vs2015-to-vs2017-upgrade/. Apart from ASP.NET web projects, this can be done without changing the target framework.
For one project at a time, you can add both .NET Framework AND .NET Core (or .NET Standard) as build targets, and then just go through each of the build errors as needed. Note that if you previously used a “TargetFramework” element, you need to change this to “TargetFrameworks” (plural):
Sometimes you may need to have different code for .NET Core and .NET Framework. For instance, there may be libraries that should only be used for .NET Core, while you use framework assemblies in .NET Framework. In those cases, you can use #if directives to tell the compiler to compile that code only for specific frameworks. Example:
Related to the previous point - sometimes, there are NuGet packages, or assembly references, that only make sense for .NET Core, and some that only make sense to .NET Framework. In your project file, these can be conditionally included like this:
Here we include the SoapCore and System.Configuration.ConfigurationManager packages only if not compiling for .NET Framework 4+.
Porting ASP.NET code to ASP.NET Core while staying compatible with both .NET Framework and Core
ASP.NET and ASP.NET Core is quite different. It’s a different way of initializing the application, different classes that area used for controllers, no more HTTP modules, and the list goes on. Therefore, when porting ASP.NET code, what we decided was to split our ASP.NET project into three projects:
One ASP.NET specific project, which contains the plumbing, lifecycle hooks for ASP.NET, HTTP modules and other .NET Framework specific constructs. This project targets only .NET Framework.
One ASP.NET Core specific project, which contains the plumbing for ASP.NET Core (startup/configuration code, etc.), middleware, and other ASP.NET Core-specific code. This project only targets .NET Core.
One project that contains all the application logic. This includes API controllers and all the logic that is defining your actual application. Add this project as a reference to the other two projects, and make sure this common project targets both .NET Core and .NET Framework.
The first two projects is fairly straight forward. However, the common project needs some thought, because ASP.NET Core controllers are a completely different type from the ASP.NET controllers. Thankfully, there’s a neat package: Microsoft.AspNetCore.Mvc.WebApiCompatShim. This allows you to re-use the typenames for ASP.NET controllers, and act as an adapter between ASP.NET Core & ASP.NET and your controller definitions. So here’s some steps you can take for this project:
Include the ASP.NET and ASP.NET Core packages conditionally, including the WebApiCompatShim package (which has the required ASP.NET Core packages as dependencies):
In the controller code, you need to have some conditional #if directives. First off, RoutePrefix is no longer a thing, but Route serves the same purpose when put on the controller level. You also need some conditional using statements:
This serves the purpose of: 1. Creating an alias for RoutePrefix with ASP.NET Core, and 2. Include the ASP.NET Core namespace.
HttpContext.Current is no longer a thing as well - so you will have to make an adjustment for this. You can use dependency injection with ASP.NET Core, and a #if directive to instead use HttpContext.Current in .NET Framework.
Keep the controller base class as before (ApiController). The WebApiCompatShim package defines ApiController for .NET Core.
Other than this, there should not be a lot of changes needed, apart from general porting of code.
Porting Workflow Foundation and Windows Communication Foundation code
I won’t write a lot here because I’m not an authority when it comes to WF and WCF. However, I want to highlight two Nuget packages that can be used to ease the transition to .NET Core:
Both of these are available in the public nuget feed. Kudos to the authors of these packages for significantly easing the transition of legacy WF and WCF code.
That’s it for now! You can reach me on Twitter if you have any comments or feedback.
less than 1 minute read
The curse of a software engineer: As soon as some application or game that you use crashes, you start attempting to debug it yourself. Without the source. Without any hope.
I really enjoy Azure DevOps for setting up my builds and releases. One feature, which really isn’t that new (it’s over a year old) is the ability to write both your build and release pipeline as code, using multi-stage pipelines and environments. It’s only recently that I’ve started to get my hands dirty on this however, and it’s wonderful. I adore Kubernetes as an app hosting platform as well, so combining these sounds just too juicy.
In my current job, one of my pet projects have been a wiki that we use across our unit (a couple of hundred people in different roles, from developers to sales). It’s based on Mediawiki, and deploying this was my first dive into Kubernetes back in the day. It has taught me a lot, knowledge that I’ve utilized in my non-pet projects as well. Today I migrated my old build and release pipelines to multi-stage pipelines.
I won’t go through the details of setting up a build pipeline using Yaml - there’s lots of resources for this. Instead I’ll focus on how you connect a Kubernetes cluster to the release stage of your pipeline using environments
About my pipeline
I’ve set up a pipeline with three stages:
Build
Release to dev
Release to prod
The Build stage builds and pushes my Docker image to a container registry, and copies my Kubernetes manifest templates to a build artifact.
After this stage is run, I have my image in my Azure Container Registry, and my Kubernetes manifest templates in the “drop” artifact.
Defining the environment in Azure DevOps
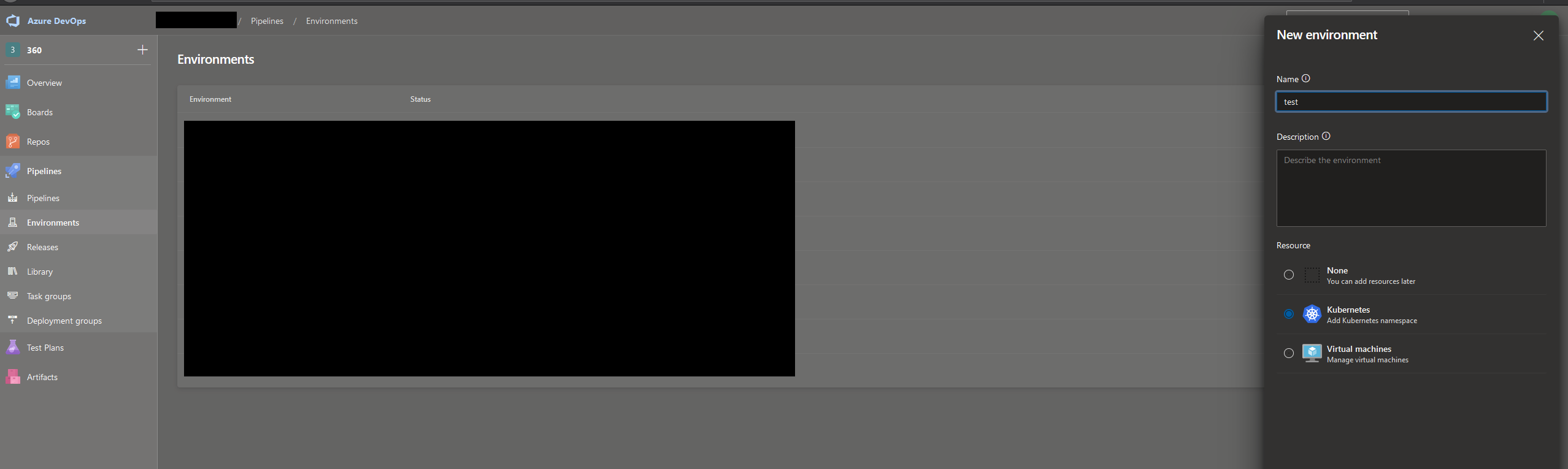
This is super easy. Go to your Azure DevOps project, and under Pipelines go to Environments. In my case, I chose to create an environment with a Kubernetes resource, which is essentially a service connection to a Kubernetes namespace. On the next page, it’s easy if you use AKS for your Kubernetes needs. All your Azure subscriptions will be listed, and you just choose the cluster you want to connect to, and the namespace you want to connect to. After the environment you can refer to this environment in your Yaml pipeline definition.
Using your newly created environment
Now let’s look at the Release to Dev stage. Notice that I’ve connected a variable group as well. This is the only way I’ve found to actually have unique secret variables per stage in a release pipeline. If they’re not secret, it’s probably easiest to include them in the pipeline yaml file itself.
-stage:Release_Devvariables:# Your variables go here!-group:'foobar-Dev'jobs:-deployment:Deploy_Wiki_Devenvironment:test.my-namespacestrategy:runOnce:deploy:steps:-task:KubernetesManifest@0displayName:'kubectlapplywikideployment'inputs:action:deploynamespace:'wiki-dev'manifests:|$(Pipeline.Workspace)/drop/wiki-pods.yml$(Pipeline.Workspace)/drop/elasticsearch.yml
There’s a few things going on here. First off, you’ll notice that instead of a “job” under the “jobs”, you’ll see a “deployment”. A deployment, as far as I’ve understood, is just a special kind of job that lets you connect it to an environment, as well as using a variety of deployment strategies for deployment. Once I dig more into this, that could be a topic for another day. Right now I’m just using it as a job to run my tasks.
In essence though, you define the deployment job, and connect that to an environment using the “environment” property. In this example here, I have defined an environment called “test” and a resource in that environment, which is a Kubernetes namespace, called “my-namespace”. On my “test” environment I can set up approvals and other validations. I can also define more Kubernetes namespaces, or even VMs, under the environment through the Azure Pipelines UI.
After the environment, you’ll see a “strategy” node. I just want to run my tasks, so I use “runOnce”, under which there are a “deploy” node, and then finally I can define my build tasks under “steps”. Here I’ve put only a Kubernetes deployment task to deploy my manifest files.
One really cool feature of using deployment jobs with environments, is that the tasks defined for this deployment job inherits the credentials used for the resources in that environment. You may notice that I haven’t put any credentials or any reference to a service connection on the KubernetesManifest task. It’s automatically picked up from the environment, or more specifically the “my-namespace” resource within the environment.
Summing up
I didn’t go into the deepest and darkest details here at all, but I hope you may find this interesting and/or helpful. It certainly is very powerful to both be able to define your build AND release pipelines in code and letting them all be source controlled. I certainly learned a lot, much of which I’m sure I’ll find a good use for in my other projects as well. And I can finally have the build AND deployment code of our wiki version controlled, which is SO useful.
Feel free to reach out if you see an obvious mistake or if you have any comments!
Ironically, my first “real” post on this blog won’t be related to coding. But I figured it’s quite relevant these days, and I wanted to share it, if for nothing else as a PSA.
More or less every social media website, and TONS of other websites and advertisement companies, use tracking cookies to monitor user behavior. Usually this is considered quite harmless, and the cookies only identify that when you visit site A, then site B, that it’s the same user visiting both. Neither site A or site B knows that your name is Bob. Then the owner of the cookie (e.g. Google) can tie that tracking cookie to your account to serve you personalized ads.
However, sometimes you may be asked for an e-mail address, your name and other information on a website. Perhaps you’re creating an account there, perhaps you’re signing up for an e-mail list. Suddenly the website you’re visiting have both the anonymous tracking cookie, AND information to connect to it. This information can be sold to third-parties, and it is.
Yesterday I learned that there exists services out there, like one called GetEmails, that lets websites identify anonymous web traffic and connect your anonymous visit to your e-mail address, your name, home address, phone number and more, for the site owners to use, based on tracking cookies.
Let that sink in… If you visit a site as an anonymous user, and that website uses this service, that website may get access to your personal contact information including your home address! That means they can both call you on your phone, send you physical mail, and in principle also sell that information to others as well. And I see no reason why scammers also can make use of this. Visit evil.com, and suddenly the scammer has your home address. If it doesn’t freak you out, it should. This is real.
Now, thankfully there’s ways to block tracking cookies. Some browsers do it by default - for instance Firefox blocks a lot of tracking cookies out of the box. Today I switched Firefox from the standard blocking mode, to strict. For those not using Firefox, most modern browsers do support blocking tracking cookies.
If you’re interested in hearing a real-life story about this, I can recommend an episode from one of the podcasts I listen to, Smashing Security, episode 190. It’s an entertaining and very relevant podcast these days.
Tl;dr: You should block third-party cookies, also known as tracking cookies!
So I’ve finally gotten around to creating a new blog. I wanted a place to write about some of the things I’m doing related to coding, software architecture and possibly other topics related to technology that I find interesting.
My intention is to try to blog a bit regularly - we’ll see how that goes!